Kafka Streams Word Count Application
The Kafka Streams word count application is the classic “Hello World!” example for Kafka Streams. It helps to introduce some main concepts of the library.
Video Tutorial
By the way, you can follow me on YouTube for more Software Engineering Content in my channel Programming with Mati.
Code
You can find the code of this project in the Github repository Kafka Streams Word Count
Application Diagram
Here is a simple diagram for this application:
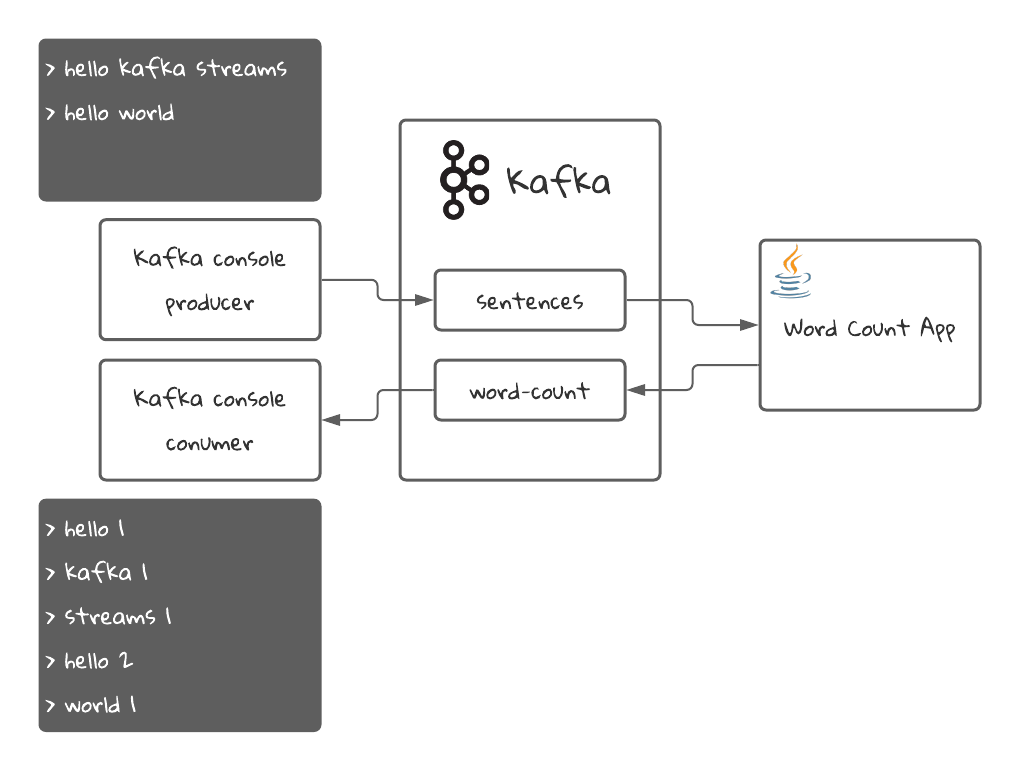
The Java application will read sentences from the sentences topic in Kafka and will count the amount of times each word has appeared in all the sentences. Then it will stream the latest count for each word into the word-count topic, which we will read with a Kafka console consumer.
Requirements
- Docker: We will use it to start Kafka and create the topics. Here is Docker’s download link
- Java 15: Download Link
- An IDE like Intellij IDEA
Running the project
Starting Kafka
First, we need to start Kafka. For that we have a docker-compose.yml file that will create the necessary resources for us. It will start a Zookeeper instance and a Kafka broker. It will also create the necessary topics using the script found in the create-topics.sh file.
docker compose -f ./docker-compose.yml up
Building and starting the application
./mvnw compile exec:java -Dexec.mainClass="com.github.programmingwithmati.kafka.streams.wordcount.WordCountApp"
Publishing a message and consuming the results
- we need to connect to the docker container to run commands on a CLI:
docker exec -it kafka /bin/bash - we create a console consumer to consume the
word-counttopic:kafka-console-consumer --topic word-count --bootstrap-server localhost:9092 \ --from-beginning \ --property print.key=true \ --property key.separator=" : " \ --key-deserializer "org.apache.kafka.common.serialization.StringDeserializer" \ --value-deserializer "org.apache.kafka.common.serialization.LongDeserializer" - Open a new terminal and connect again to the kafka docker container:
docker exec -it kafka /bin/bash - Create a console producer to insert sentences in the
sentencestopic:kafka-console-producer --topic sentences --bootstrap-server localhost:9092 - In your console producer, insert the following messages:
>Hello kafka streams >Hello world - In your console consumer terminal, you should see the following result:
hello : 1 kafka : 1 streams : 1 hello : 2 world : 1What you see is the words that we inserted in step 5, followed by the amount of times that word was processed. That’s why the word
helloappears twice.
Understanding the Topology
The topology of a Kafka Streams Application refers to the way in which the data will be processed in the stream. When we define a Topology, what we are doing is defining a set of operations which will transform the data as it is streamed. The programming paradigm used by Kafka Streams is called dataflow programming. The logic of the application is structured as a Direct Acyclic Graph (DAG). There are several advantages of this paradigm:
- Easy to understand
- Easy to standardize
- Easy to visualize
- Easy to parallelize
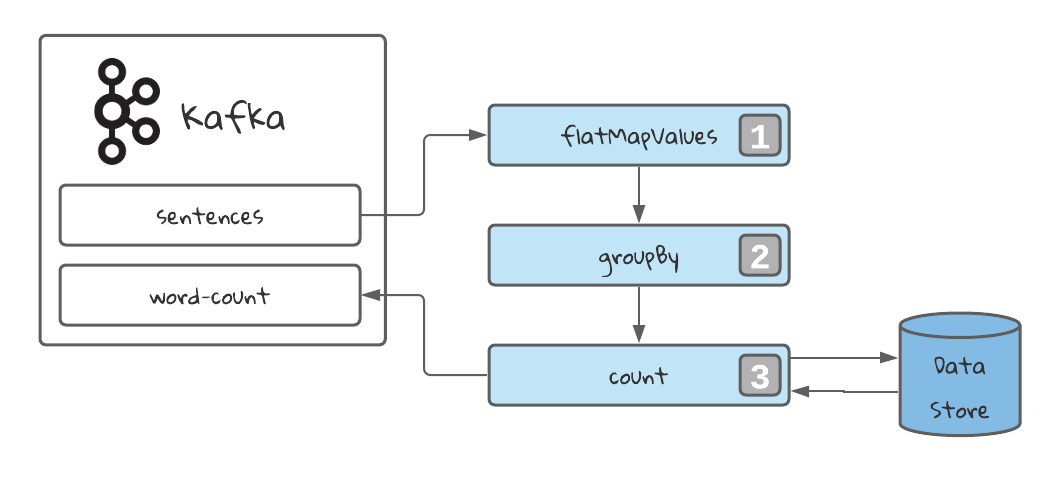 1️⃣ Flat Map operation to map 1 record into many. In our case, every sentences is mapped into multiple records: one for each word in the sentence. Also the case is lowered to make the process case-insensitive.
1️⃣ Flat Map operation to map 1 record into many. In our case, every sentences is mapped into multiple records: one for each word in the sentence. Also the case is lowered to make the process case-insensitive.
2️⃣ Group By the stream selecting a grouping key. In our case, the word. This will always return grouped stream, prepared to be aggregated. It will also trigger an operation called repartition. We will learn more about this later.
3️⃣ Count every appearance of the key in the stream. This will be stored in a data store.
Finally, we stream the results into the topic word-count. We can stream a table using the method toStream, which will stream the latest value that was stored for a given key, everytime that key is updated.
Taking a look at the code
In the class WordCountApp we can see the following code:
public class WordCountApp {
public static void main(String[] args) {
// 1. Load Kafka Streams properties
Properties props = getConfig();
StreamsBuilder streamsBuilder = new StreamsBuilder();
// 2. Build the Topology
streamsBuilder.<String, String>stream("sentences")
.flatMapValues((key, value) -> Arrays.asList(value.toLowerCase().split(" "))) // Flat Map Values splits the sentences into words, and creates multiple entries in the stream
.groupBy((key, value) -> value) // groupBy groupes all values in the stream by a given criteria, in this case, the same word. It becomes the key of the stream
.count(Materialized.with(Serdes.String(), Serdes.Long())) // count converts the KStream in a KTable, storing the data in a Data Store. By default is RocksDB
.toStream() // Transform the KTable into a KStream to stream every change in the state
.to("word-count", Produced.with(Serdes.String(), Serdes.Long())); // Finally, stream the results into the word-count topic
// 3. Create the Kafka Streams Application
KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(), props);
// 4. Start the application
kafkaStreams.start();
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread(kafkaStreams::close));
}
// ...
}
As you can see, the High Level DSL is very easy and intuitive to use. The fact that works as a fluent API makes it very easy to read an maintain as well.
Next Tutorial
In our next tutorial, we will be creating a Streams application to transform Speech into text and to parse voice commands. We will use Stateless operations, and we will learn about the interface KStream.